前言:
我最近一直在hw值班超赞的圆形花纹笔刷,看着红队老板封杀不了的IP,我开始怀疑他们用了什么方法。
827的日子开始了
自动更换代理ip常用的三种方法
1.使用第二个广播ip配合ip魔盒
2.流量转到 tor 代理
3.ip替换自定义代码
本文主要讲第三种方式(因为最简单也最便宜)
demo中使用的url是我的域名微票儿多线程注册机,所以没有脱敏
环境
图书馆
队列
系统
多个代理 ip 可用
(可选择是否构建)
根据个人需要,如果没有稳定的代理ip,建议自建。
文章主要使用代码。如果使用自己的代理ip,可以改代码。
开源就大佬
地址:
脚本的总体思路
1.读取字典文件
2.验证读取的代理ip是否可以使用
3.使用代理发送包
脚本分块1.对于读取字典文件,这个其实没什么好说的
f = open('dir.txt', 'r')#dir为你的字典文件
for i in f:
print(i)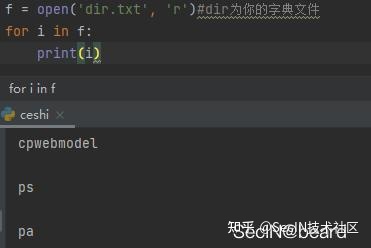
2.验证代理是否可用
`
def get_proxy():#通过api获取数据的
while True:
proxy = requests.get("http://ip:5010/get/").json().get("proxy")#通过proxy_tools api进行获取数据
try:#如果报错就代表没有代理ip 出现了问题
proxys = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
a = requests.get("http://www.xxxx.cn/", proxies=proxys, timeout=1, verify=False).status_code#此处主要是验证,所以给一个可以访问的网站就行
if a == 200:return proxys#如果访问正常就代表代理可用返回代理ip
except :#调用delete_proxy删除代理ip
delete_proxy(proxy)
def delete_proxy(proxy):#删除代理ip
requests.get("http://p:5010/delete/?proxy={}".format(proxy))通过get调用api获取代理ip
由于无法使用代理会报错
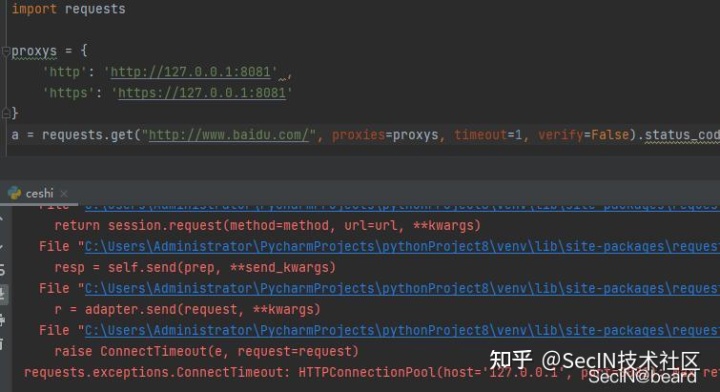
所以在外层添加了一个无限循环。当代理无法使用时,会重新获取,直到获得可用的代理。
3.使用代理发送包
def req_proxy(url):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'}
proxy=get_proxy()
try:#超时就跳出,重新获取代理ip
tar = requests.get(url, headers=headers, proxies=proxy, timeout=10, verify=False)
if tar.status_code != 404: # 筛选状态码
urls = {url+" Is status:"+str(tar.status_code)}
print(list(urls))
except :
pass因为菜,用最简单的状态码判断
完整代码
上面实现了我想要的微票儿多线程注册机3D Studio MAX,现在是时候组装了
`
import requests
def get_proxy():
while True:
proxy = requests.get("http://xxx:5010/get/").json().get("proxy")
try:
proxys = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
a = requests.get("http://xxx.org/get", proxies=proxys, timeout=1, verify=False).status_code
if a == 200:return proxys
except :
delete_proxy(proxy)
def delete_proxy(proxy):
requests.get("http://xxx:5010/delete/?proxy={}".format(proxy))
def req_proxy(url):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'}
proxy=get_proxy()
try:#超时就跳出,重新获取代理ip
tar = requests.get(url, headers=headers, proxies=proxy, timeout=10, verify=False)
if tar.status_code != 404: # 筛选状态码
urls = {url+" Is status:"+str(tar.status_code)}
print(list(urls))
except :
pass
url="http://www.allbeard.cn/"
f = open('dir.txt', 'r')#dir为你的字典文件
for i in f:
req_proxy(url+i)有两个放映。以这个速度荷花笔刷下载2,跑完一个脚本就过年了(太慢了)。
多线程完整版
import requests, sys, threading
from queue import Queue
def get_proxy():
while True:
proxy = requests.get("http://xxx:5010/get/").json().get("proxy")
try:
proxys = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
a = requests.get("http://xxxx.org/", proxies=proxys, timeout=1, verify=False).status_code
if a == 200:return proxys
except :
delete_proxy(proxy)
def delete_proxy(proxy):
requests.get("http://xxx:5010/delete/?proxy={}".format(proxy))
# 多线程实现扫描目录
class DirScan(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self.queue = queue
def run(self):
# 获取队列中的URL
while not self.queue.empty():
url = self.queue.get()
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'}
proxy=get_proxy()
try:#超时就跳出,重新获取代理ip
tar = requests.get(url, headers=headers, proxies=proxy, timeout=10, verify=False)
if tar.status_code != 404: # 筛选状态码
urls = {url+" Is status:"+str(tar.status_code)}
print(list(urls))
except :
pass
def start(url, su):
queue = Queue()
f = open('dir.txt', 'r')
for i in f:
queue.put(url + i.rstrip('\n'))
# 多线程
threads = []
thread_count = int(su)
for i in range(thread_count):
threads.append(DirScan(queue))
for t in threads:
t.start()
for t in threads:
t.join()
if __name__ == "__main__":#入口
print('+------------------------------------------')
print('+ \033[34m不会联盟 by beard \033[0m')
print('+ \033[34m工具名:随机代理的目录扫描工具 \033[0m')
print('+ \033[36m使用格式: python3 proxypath.py http://xxxx/ \033[0m')
print('+------------------------------------------')
try:
url = sys.argv[1]
except:
print("按照格式输入 python3 proxypath.py http://xxxx/ ")
sys.exit()
count = 10
start(url, count)代码简单,请轻喷

发表评论